

RELATED ARTICLES
SHARE ARTICLE
Syslog Logging with Fluentd - Secure Logging Done Right
Learning Objectives
For the DevOps engineer deploying and managing logging infrastructure in a hybrid cloud ecosystem is an important part of the software lifecycle for your fellow developers and engineers.
Syslog is a popular protocol that is supported on nearly every type of server. From legacy routers, switches and firewalls to modern containers powered by Docker you will find syslog configurations. The challenge with syslog has traditionally been aggregating these on a server and searching them.
In this article, we will cover how to use Fluentd to forward syslog traffic to Mezmo, formerly known as LogDNA.
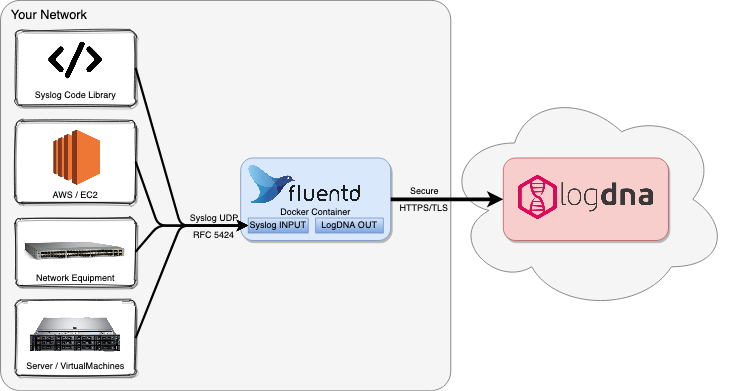
Prerequisites
- A basic understanding of Fluentd.
- A basic understanding of Docker and Docker Compose.
- A computer with Docker engine and Docker Compose installed.
- A running instance of rsyslogd, or any device or application that supports emitting syslog over UDP in RFC 5424 format to your docker container.
Fluentd is really handy in the case of applications that only support UDP syslog and especially in the case of aggregating multiple device logs to Mezmo securely from a single egress point in your network. Fluentd with the Mezmo plugin aggregates your logs to Mezmo over a secure TLS connection.
Before a DevOps engineer starts to work with Fluentd, they have to know the actors of the logging process: the logging stack components.
The Components of the Logging Stack
Log analysis can’t be done without log collectors. But, to ensure the logging process is managed correctly, we need a logging stack. A logging stack is a set of components working together to ensure proper logging management.
Standard components of a logging stack are:
- Log exporter
- Log collector (listens for log input, in this case UDP syslog)
- Log storage
- Log visualization
How does Fluentd as a log collector interact in this stack? To answer this question a DevOps engineer first has to know what Fluentd is.
What is Fluentd and how does it work?
Fluentd is built by Treasure Data as a member project of the CNCF (Cloud Native Computing Foundation). All components of Fluentd are available under the Apache 2.0 license.
Fluentd is an open-source data collector written in Ruby. It lets you unify the data collection and consumption to allow better insight into your data. Fluentd scrapes logs from a given set of sources, processes them (converting them into a structured data format) and then forwards them to other services like Mezmo, object storage, etc. Fluentd also works with Elasticsearch and Kibana, together known as the EFK stack.
It works with 300+ log storage and analytic services, making it a very compatible tool.
Syslog Fluentd with Mezmo Overview
When a DevOps engineer starts with ingesting syslog logs with Fluentd, there are two main parts to the Fluentd configuration. There’s a source block to capture a syslog source and the match block, which collects and forwards the logs to Mezmo.
The source block
To start scraping the syslog logs, a DevOps engineer first has to create the following “source” configuration in the fluent.conf file.
The @type is an inbuilt directive understood by Fluentd. With this, Fluentd knows how and where to retrieve the logs. Another example is “http”, which instructs Fluentd to collect data by using the GET method on the HTTP endpoint.
The match block to forward logs to Mezmo
The second section we will use to configure logging output to Mezmo is to define a match block as seen below.
The @type is a directive that calls the Mezmo plugin for fluentd. The setting for <pre data-enlighter-language="less">
$npm install ip morgan logdna-winston @types/ip --save // api_key</pre> needs to be configured with your ingestion key for Mezmo.
Docker-compose quick-start
To help DevOps engineers onboard quickly, we have created a git repository with a Docker image ready to go with the Fluentd Mezmo plugin and integration. You can set this up quickly with Docker Compose and experiment with the rulesets that fit your needs.
You can clone the repository below and follow this tutorial to get fluentd up and running.
Configure your Docker Compose Fluentd image for Mezmo
First you’ll need to select the version and Docker image that’s right for you. In our example we are going to use the latest version of Fluentd v1.12 along with the Debian container image. This can be found in the root of the repository under
Using your text editor of choice, open the docker-compose.yml file and customize the environment variables under the
service block.
Below is a brief table summarizing the available variables and their meaning. [Note: Quotes are not required and shouldn’t be used when setting these variables.]
Bringing the Docker container up
From within the
directory you can start the Fluentd Mezmo Docker image with
That’s it! You’re ready to send your logs via syslog to the server running Docker Compose on port 5140. NOTE: You may have to configure firewalld, iptables or UFW rules to permit inbound traffic on the syslog port. Most Linux distributions ship with a software firewall enabled by default.
Wrap-Up
Analyzing logs is an important part of being a DevOps engineer in any large-scale distributed environment. As a part of the logging stack, Fluentd is extremely valuable as a data collector with its input filters. We hope this article helps you get started with the Fluentd stack on Mezmo.
It’s time to let data charge

.svg)






